

Once upon a time, I worked at a hosting company… sadly, after a hardware upgrade gone wrong, the database server behind a customer’s website was sitting open on a data center floor with a cracked motherboard during their launch event. We provided an overall yearly uptime better than three nines (99.9%, or 52 and half minutes per year of downtime) for that customer, but it didn’t matter because we failed when it mattered most.
Uptime nines aren’t too tough to calculate, but they’re kind of unforgiving. Let’s start with a simple goal, 99% availability. Two nines gives you 1.68 hours of downtime per week — that’s a pretty reasonable maintenance period. Lots of tasks could be completed in that time, and if you’re measuring monthly or yearly there’s time to plan and do big projects.
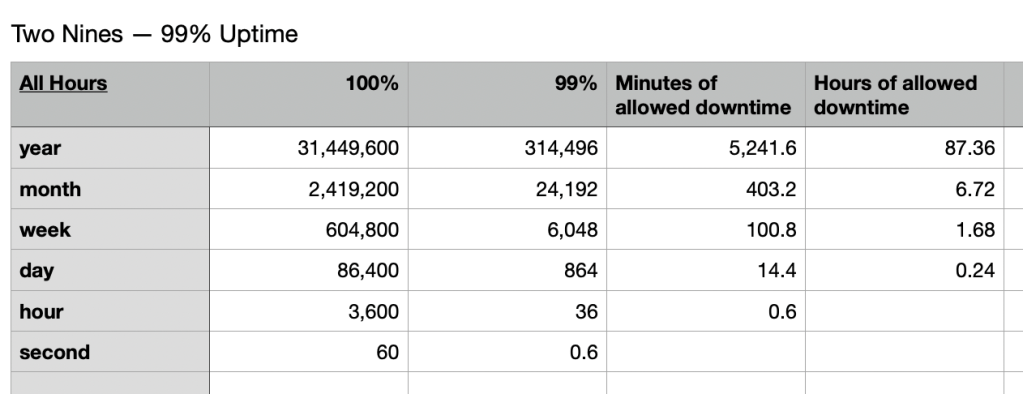
However, five nines has been the goal for a lot of my career, 99.999% uptime. Now your weekly budget is six seconds… there’s no regular patching under this kind of maintenance goal.
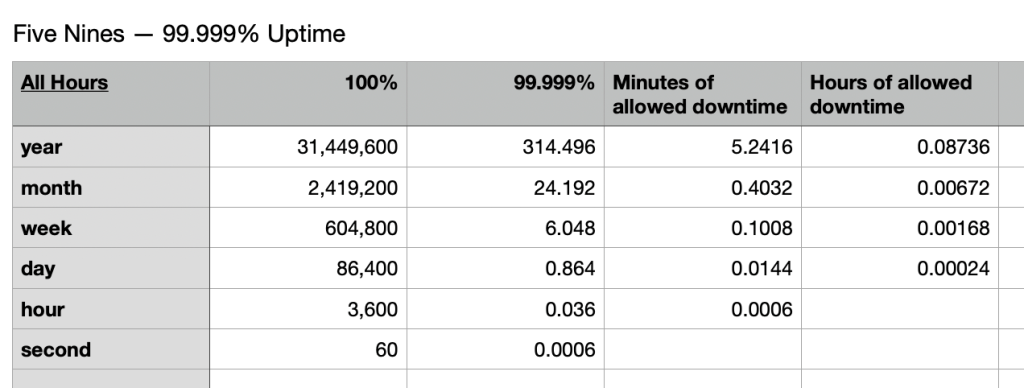
A lot of ways have been proposed to tackle that, including rethinking what’s actually under the stringent Service Level Agreement (SLA), clustering the systems, and redesigning with containerized micro services. Something from that menu is required (but not solely sufficient!) to consider a five nines goal.
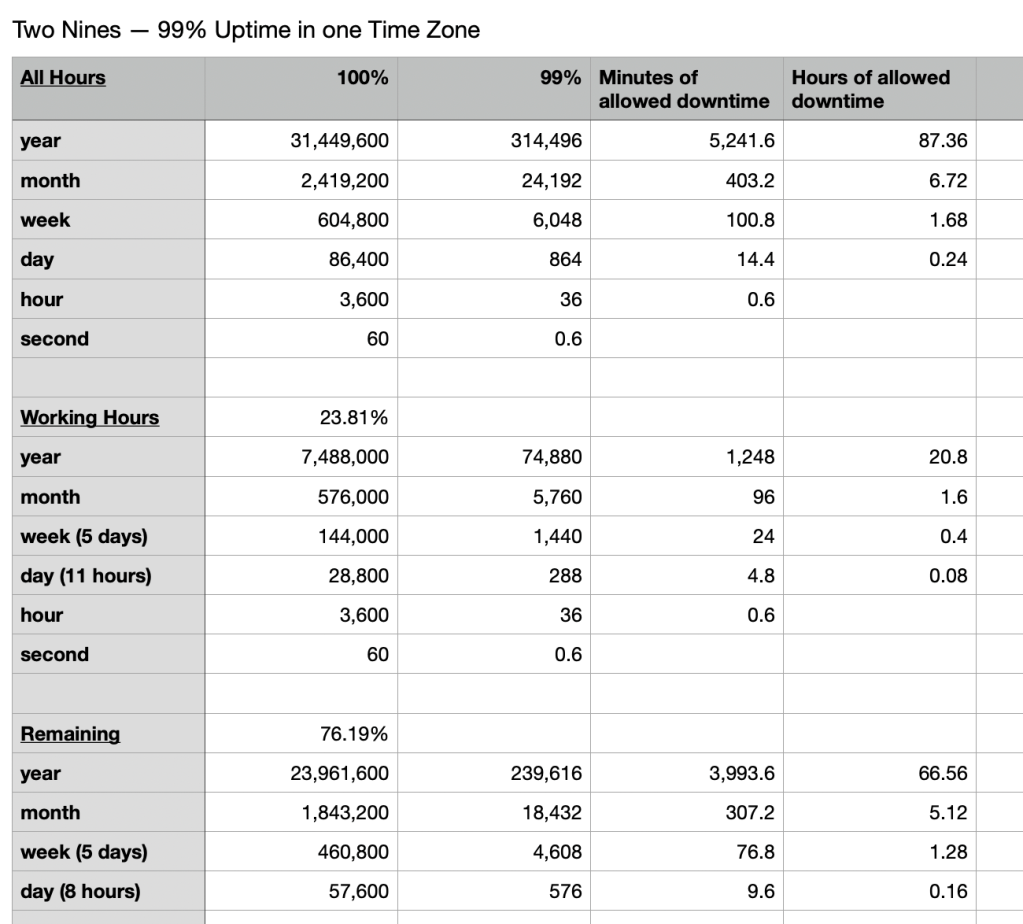
Downtime during a customer’s desired usage hours hurts more than downtime when that customer is sleeping. So what’s the nines measurement look like if core hours downtime is weighted appropriately? A global business technically has customer usage hours all the time, but many businesses aren’t as global as all that. They’ve got core hours, where the majority of activity is happening. Still, there’s a lot of variance, so let’s keep it simple at first: a single timezone, with a forty hour work week. Now a two nines maintenance budget has dropped from 1.68 hours a week to 1.28 hours a week. It’s still manageable to keep systems patched, but the window is tightening.
North American operations turns the screw again — four timezones makes the eight hour work day into an eleven hour day. Two nines is now 1.13 hours a week, and five nines is 3.5 minutes a year.
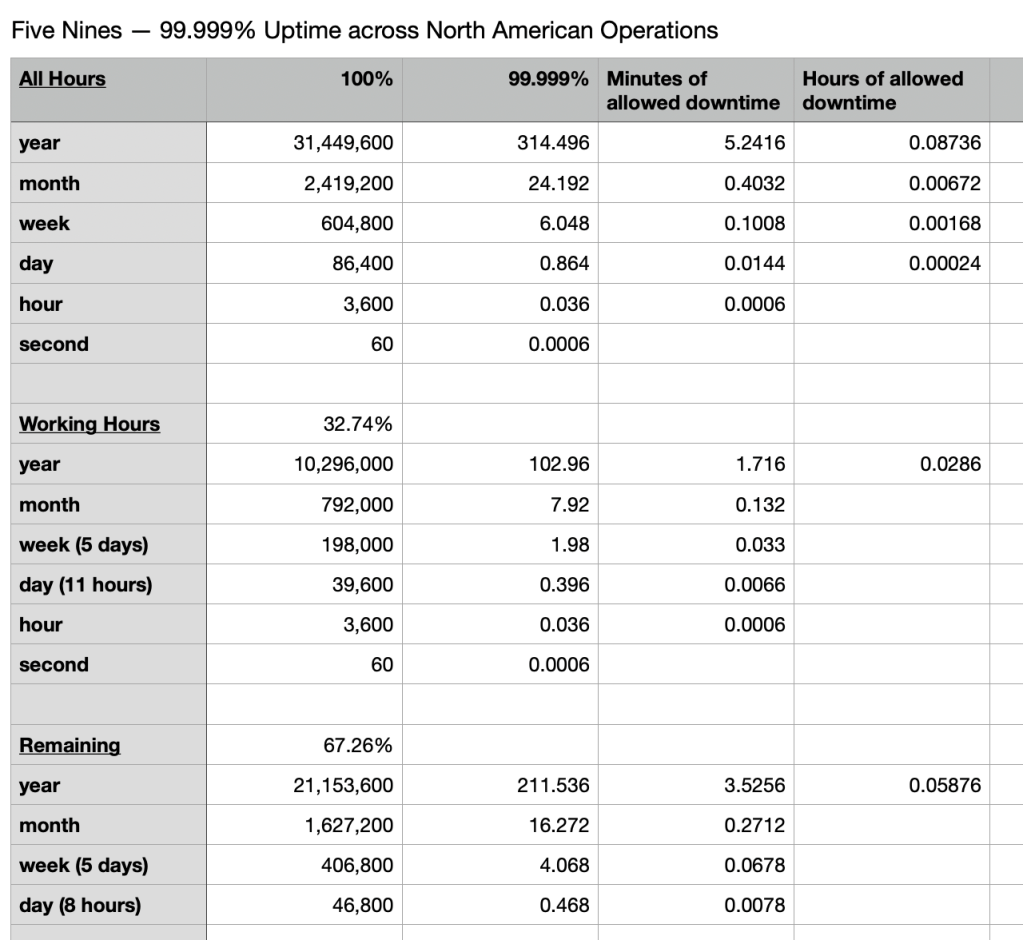
And that’s whycome the vast complexity of modern architecture exists: containerized micro services, infrastructure and functions as services, elastically scaled clouds across multiple layers and vendors with concomitant visibility gaps. To be clear, none of that prevents downtime, it just makes it possible to design for downtime avoidance.
One other trick in the playbook is worth mentioning… simply paying out. Companies with 100% SLAs on a component aren’t necessarily designing for nuclear reactor levels of uptime. Maybe they did the math and found it would be cheaper if they just wrote checks to cover their downtime.
